肆叁小灶第11讲 强化学习
肆叁小灶第 11 讲,介绍了强化学习的相关知识。
笃实 43 班的同学们大家好。本周我们在《人工智能基础》课程中学习了强化学习的相关知识,然而不少同学反馈内容太多、讲的太快,难以消化。为了帮助大家完成学习任务,我们在本次肆叁小灶中将带大家回顾课堂中讲解的强化学习算法,并补充一些课时所限没有涉及的改进方法和最新进展。超出课程要求的内容段落开头会有一个“补充”的标记,大家可以根据自己的兴趣选择性地阅读。
强化学习的核心思想是:环境中的智能体通过与环境交互获得的奖励信号来学习最优策略。形式化地,智能体在每轮起始时,观测到环境状态 $s_t$,根据观测结果在动作空间中选取一个动作 $a_t$,环境接收到动作后返回一个奖励信号 $R_{t+1}$ 并发生状态转移 $s_t\to s_{t+1}$,智能体根据奖励信号调整策略,并在下一轮起始观测到新的环境 $s_{t+1}$,直至达到某个终止状态。
强化学习算法执行的就是“根据奖励信号调整策略”这一步,目标都是最大化智能体在环境中获得的累积奖励,也即回报 $G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots$,其中 $\gamma\in [0,1]$ 用于权衡当前与未来奖励的重要程度。从类别上看,强化学习算法可以分为基于值函数的方法和基于策略的方法。接下来我们一一介绍。
一、基于值函数的方法
值函数是用于评估某个状态或在某个状态下执行某个动作的好坏程度的函数,一般直接以在某个策略下的回报 $G_t$ 的期望来定义,即 $V^\pi(s) = \mathbb{E}_\pi[G_t|s_t=s]$ 和 $Q^\pi(s,a) = \mathbb{E}_\pi[G_t|s_t=s,a_t=a]$。基于值函数的方法的核心思想是:通过学习到的值函数来获得策略,如采用 $\epsilon$-贪心策略,即以 $1-\epsilon$ 的概率选择在当前状态下 $Q^\pi(s,a)$ 最高的动作,以 $\epsilon$ 的概率随机选择其他动作。这样问题就转变成了如何学习 $Q^\pi(s,a)$。
一个最简单的方法是:直接从状态 $s$ 出发执行动作 $a$,随后采用当前的策略继续执行,直到达到某个终止状态,从而获得一个回报 $G_t$。根据 $Q^\pi(s,a)$ 的定义,$G_t$ 就是 $Q^\pi(s,a)$ 的一个无偏估计,因此我们可以将 $G_t$ 作为 $Q^\pi(s,a)$ 的一个样本来进行学习,这就是蒙特卡洛(MC)方法。
为了解决蒙特卡洛法方差较大的问题,我们引入了时序差分(TD)方法。时序差分方法的思想是使用贝尔曼方程 $V^\pi(s) = \sum_{a} \pi(a|s) \sum_{s’,r} p(s’,r|s,a)[r + \gamma V^\pi(s’)]$,在状态 $s$ 下根据当前策略 $\pi$ 选择一个动作 $a$,随后观测到奖励 $R$ 和下一个状态 $s^\prime$,根据贝尔曼方程可知 $R + \gamma V^\pi(s^\prime)$ 是 $V^\pi(s)$ 的一个方差较小的有偏估计,我们可以将 $R + \gamma V^\pi(s^\prime)$ 作为 $V^\pi(s)$ 的一个样本来进行学习,这就是 TD(0) 方法。
补充 至此我们自然会想:能否将 TD(0) 方法的低方差和蒙特卡洛法的无偏性结合起来呢?答案是肯定的,这就是 N-step TD(0) 方法和 TD($\lambda$) 方法。N-step TD(0) 方法的思想是:在状态 $s$ 下根据当前策略 $\pi$ 选择一个动作 $a$,随后根据当前策略 $\pi$ 连续执行 $N$ 步,根据观测到的奖励 $R_{t+1}, R_{t+2}, \cdots, R_{t+N}$ 和下一个状态 $s_{t+N}$ 来构造一个回报 $G_t^{(N)} = R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{N-1} R_{t+N} + \gamma^N V^\pi(s_{t+N})$,将 $G_t^{(N)}$ 作为 $V^\pi(s)$ 的一个样本来进行学习。可见蒙特卡洛方法和 TD(0) 方法分别是 N-step TD(0) 方法的两个极端情况:前者对应 $N\to +\infty$,后者对应 $N=1$。TD($\lambda$) 方法则更进一步,取 $(1-\lambda)(G_t^{(1)} + \lambda G_t^{(2)} + \lambda^2 G_t^{(3)} + \cdots)$ 作为 $V^\pi(s)$ 的一个样本来进行学习,其中 $\lambda\in [0,1]$ 用于权衡不同步数的回报的重要程度。
补充 但前面所说的几种时序差分方法仍然有一个问题:它只能估计 $V^\pi(s)$,但为了获得策略我们需要估计的是 $Q^\pi(s,a)$。我们做一个简单的修改:把 $V^\pi(s^\prime)$ 替换成在 $s^\prime$ 下再根据当前策略 $\pi$ 选择一个动作 $a^\prime$,即 $R + \gamma Q^\pi(s^\prime,a^\prime)$,就得到了 SARSA 方法。显然,SARSA 方法也可以使用前面所说的 N-step 和 $\lambda$ 的思想来进行改进。
但实际中,我们更倾向于选择在 $s^\prime$ 下 $Q^\pi(s^\prime,a)$ 最高的动作来进行学习,即把 $Q^\pi(s^\prime,a^\prime)$ 替换成 $\max_{a^\prime} Q^\pi(s^\prime,a^\prime)$,即 $R + \gamma \max_{a^\prime} Q^\pi(s^\prime,a^\prime)$,就得到了 Q-learning 方法。可见 Q-learning 方法是一个异策略的方法:在状态 $s^\prime$ 下选择动作时并未根据当前策略 $\pi$ 来选择动作,而是直接贪心地选择了值函数最高的动作。
Q-learning 方法具有很好的推广性。前面为了简化分析,我们假设状态空间是离散的,但在实际应用中,状态空间往往是连续的,在连续空间中我们就不能使用一个表格来存储 $Q^\pi(s,a)$ 的值了,这时我们可以使用一个以 $\theta$ 为参数的函数近似器(如神经网络)来近似 $Q^\pi(s,a)$,这个近似器接收状态 $s$ 和动作 $a$ 作为输入,输出 $Q^\pi(s,a)$ 的近似值。和传统 Q-learning 一样,我们使用 $R + \gamma \max_{a^\prime} Q^\pi_\theta(s^\prime,a^\prime)$ 来优化这个近似器的参数 $\theta$,这就是深度 Q 网络(DQN)方法。
然而,由于基于值函数的方法都依赖 $\epsilon$-贪心策略,因此很难推广到连续动作空间中。为了解决这个问题,我们引入了基于策略的方法。
二、基于策略的方法
基于策略的方法的核心思想是:我们直接使用一个参数为 $\theta$ 的函数近似器来近似策略 $\pi(a|s)$,这个近似器接收状态 $s$ 作为输入,输出在状态 $s$ 下选择动作 $a$ 的概率 $\pi_\theta(a|s)$。具体地,如果动作空间离散,我们让近似器输出每个动作的一个评分,随后通过 softmax 函数将评分转化为概率;如果动作空间连续,我们让近似器输出均值和方差两个参数,随后通过高斯分布来采样动作。这样,基于值函数的方法难以处理的连续动作空间问题在基于策略的方法中就迎刃而解了。
可见,基于策略的方法本质上是在优化一个参数为 $\theta$ 的策略近似器。我们都知道优化过程需要梯度信号,为此我们需要先定义一个策略的性能度量指标 $J(\theta)$,然后计算 $J(\theta)$ 关于 $\theta$ 的梯度 $\nabla_\theta J(\theta)$,最后使用梯度上升的方法来优化 $\theta$。在时间步是离散的,即回合制的情况下,一个自然的性能度量指标就是策略 $\pi$ 下的初始状态的值函数 $V^\pi(s_0)$;$J(\theta)$ 的梯度则由策略梯度定理给出:其梯度正比于 $\mathbb{E}_{\pi_\theta} [Q^\pi(S_t,A_t)\nabla_\theta \log \pi_\theta(A_t|S_t)]$。
补充 这个定理的证明过程见下图:

由于 $\nabla_\theta \log\pi_\theta(A_t|S_t)$ 可以直接通过近似器的反向传播来计算,因此我们只需要估计 $Q^\pi(S_t,A_t)$ 就可以计算出策略梯度了。和前面一样,我们可以直接使用蒙特卡洛方法估计 $Q^\pi(S_t,A_t)$ 来计算策略梯度,这就是 REINFORCE 方法。
补充 为了降低方差,我们可以引入一个基线函数 $b(S_t)$,将 $Q^\pi(S_t,A_t)$ 替换成 $Q^\pi(S_t,A_t) - b(S_t)$,可以证明这个替换并不会影响策略梯度的计算。显然,一个很好的基线函数就是状态值函数 $V^\pi(S_t)$,我们记引入了价值函数为基线的 $Q^\pi(S_t,A_t) - V^\pi(S_t)$ 为优势函数 $A^\pi(S_t,A_t)$。我们可以使用一个以 $\omega$ 为参数的函数近似器来近似 $V^\pi(S_t)$,每次以 $A^\pi(S_t,A_t)\nabla_\omega V^\pi_\omega(S_t)$ 为梯度信号来优化这个近似器的参数 $\omega$。
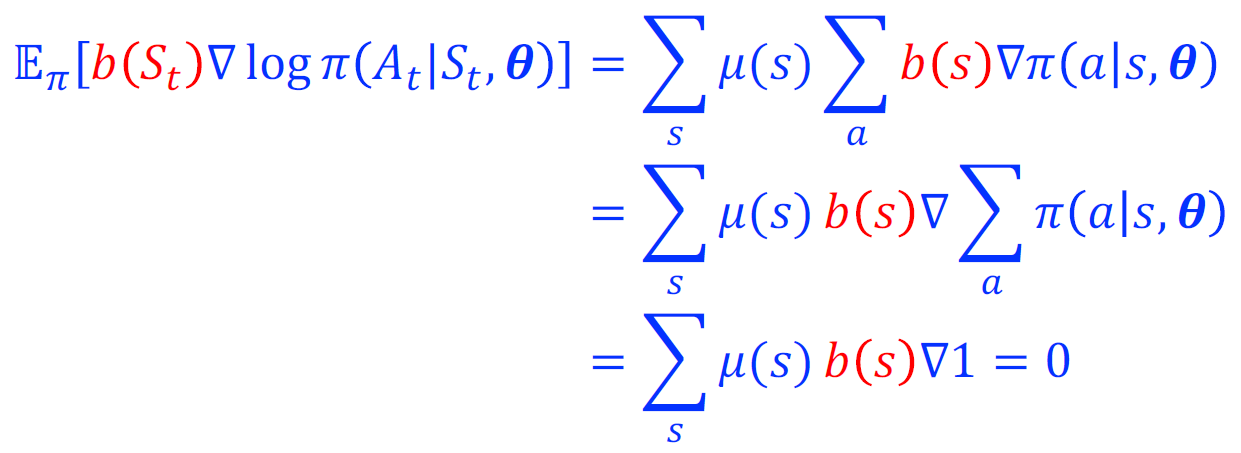
补充 我们也可以更进一步,直接把 $Q^\pi(S_t,A_t)$ 的估计方法也换成一个以 $\omega$ 为参数的函数近似器。采用 TD(0) 的思想,每次以 $(R + \gamma Q^\pi_\omega(S^\prime,A^\prime)- Q^\pi_\omega(S,A))\nabla_\omega Q^\pi_\omega(S,A)$ 为梯度信号来优化这个近似器的参数 $\omega$,这就是 One-Step Actor-Critic 方法。同理,我们也可以使用 N-step 和 $\lambda$ 的思想来进一步改进。
三、补充 现代强化学习方法
近两年,强化学习为大模型的性能提升做出了重要贡献,涌现了许多创新方法。我们在这里沿时间顺序,简要介绍三个具有代表性的现代强化学习方法的核心思想:TRPO、PPO、GRPO。
TRPO 的两个核心思想是异策略学习和信赖域更新。为了将异策略学习引入基于策略的方法,我们只需要进行一步推导:$J(\theta)=\mathbb{E_{\tau\sim \pi_\theta}} G(\tau)=\mathbb{E_{\tau\sim \pi_{\theta_{old}}}} \left[\frac{\mathbb{P}(\tau|\pi_\theta)}{\mathbb{P}(\tau|\pi_{\theta_{old}})} G(\tau)\right]$。我们使用这个思想改写训练目标:每次在 $\theta_{old}$ 的一个信赖域内取最优的 $\theta$ 来更新策略。其中信赖域的概念是:我们希望每次更新的 $\theta$ 都不要离 $\theta_{old}$ 太远,以防训练不稳定。其大小通过 $\mathbb{E_{\pi_{\theta_{old}}}} [\mathrm{KL}(\pi_{\theta_{old}}(\cdot|s),\pi_\theta(\cdot|s))] \leq \delta$ 来控制,其中 KL 散度我们在肆叁小灶第7讲中介绍过,是用于衡量两个概率分布之间的差异程度的一个指标。
PPO 则在 TRPO 的基础上做了两处优化:其一,将 KL 散度硬约束转化为软的正则项,即在目标函数中引入 $-\beta \mathrm{KL}\left(\pi_{\theta_{old}}(\cdot|s),\pi_\theta(\cdot|s)\right)$,其中 $\beta$ 是一个动态参数,如果前一轮更新的 KL 散度过大,则增大 $\beta$ 来加强正则项的约束,反之则减小 $\beta$ 来放松正则项的约束;其二,使用剪切函数来限制 $\frac{\mathbb{P}(\tau|\pi_\theta)}{\mathbb{P}(\tau|\pi_{\theta_{old}})}$ 的范围,即 $\mathrm{Clip}\left(\frac{\mathbb{P}(\tau|\pi_\theta)}{\mathbb{P}(\tau|\pi_{\theta_{old}})},1-\epsilon,1+\epsilon\right)$,其中 $\epsilon$ 是一个超参数,用于降低更新的方差。
然而,注意到从引入了基线的 REINFORCE 方法到 PPO 方法,训练目标中一直存在一个优势函数 $A^\pi_\theta(s,a)=Q^\pi_\theta(s,a)-V^\pi_\theta(s)$,其中 $V^\pi_\theta(s)$ 的估计需要一个单独的函数近似器,这就导致训练所需的资源翻了一倍。为了解决这个问题,GRPO 在状态 $s$ 下采样多个动作 $a_1,a_2,\cdots,a_K$,并直接把 $A^\pi_\theta(s,a_i)$ 取成 $\frac{R(s,a_i)-\mathrm{avg}(R(s,a))}{\sqrt{\mathrm{Var}(R(s,a))}}$。值得一提的是,$R(s,a_i)$ 本应是 $G_t(s,a_i)$,但在大模型的推理任务中,奖励信号一般只在回答结束时返回一次,因此我们直接取 $R(s,a)$ 来代替 $G_t(s,a)$。
GRPO 自 2024 年发布以来,有很多工作在它的基础上做了改进,取得了更好的性能。比如致力于提升训练效率的 DAPO、着力于解决训练稳定性的 GSPO 和旨在修正目标函数中的偏差的 Dr.GRPO 等等。但由于种种原因,如今很多新的工作仍然使用的是标准版的 GRPO 方法,因此我们在这里就不再赘述了。
后记
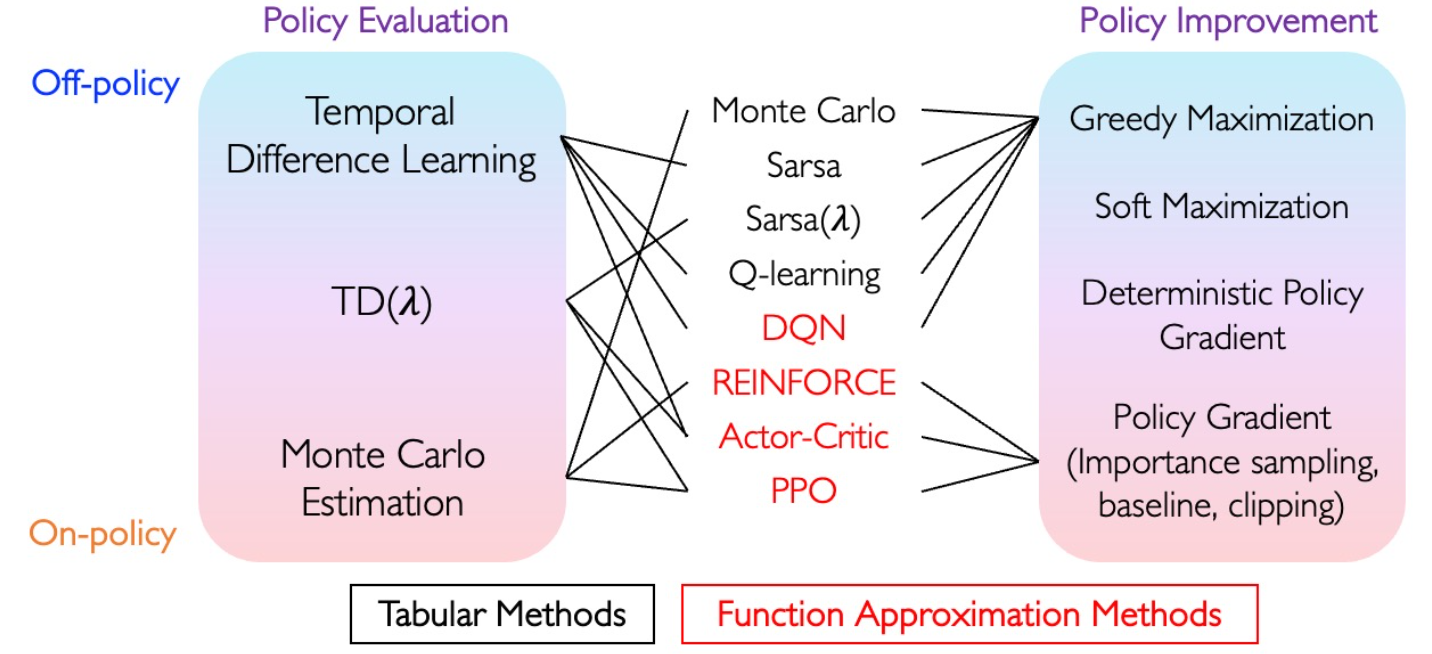
最后,我们提供一个图表来总结一下本讲介绍的强化学习算法:
对于感兴趣的同学,我们推荐以下资料进行扩展学习:
- 龙明盛,《机器学习》《深度学习》
- 合集·大语言模型时代的强化学习系列
- DeepSeek-R1 技术报告
- 各大期刊和会议的最新论文
希望本期肆叁小灶能帮助大家更好地理解强化学习的相关知识。祝大家早日顺利完成第二次作业!